
泰坦尼克号海难生存人员预测
1 | # 导入需要的库 |
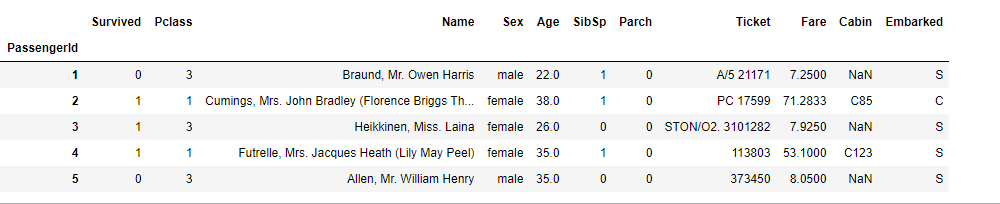
1 | data.info() |
不涉及到训练集和测试集之间相互影响的
删除缺失值过多的列,和观察判断来说和预测的y没有关系的列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34#删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)
#处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法
data["Age"] = data["Age"].fillna(data["Age"].mean())
# 该函数主要用于滤除缺失数据。
data = data.dropna()
#将分类变量转换为数值型变量
#将二分类变量转换为数值型变量
#astype能够将一个pandas对象转换为某种类型,和apply(int(x))不同,astype可以将文本类转换为数字,用这个方式可以很便捷地将二分类特征转换为0~1
#决策树不能处理文字类型,将Sex和Embarked转为数字 data["Sex"]=='male'得到的是Series类型,均为false和true
data["Sex"] = (data["Sex"]== "male").astype("int")
#将三分类变量转换为数值型变量
# unique():返回参数数组中所有不同的值,并按照从小到大排序可选参
# tolist()用于将数组或矩阵转为列表
# =============================================================================
# #将分类变量转换为数值变量
# # 将二分类变量转化为0,1变量
# # astype能够轻松的将pandas中文本变量转换为数值型变量
# data['Sex'] = (data['Sex'] == 'male').astype("int")
# data.head()
# =============================================================================
labels = data["Embarked"].unique().tolist()
print("The label is ",labels)
#print(data["Embarked"])
print(labels.index('Q'))
#注意:此处的x是data["Embarked"]里面的SCQ的值,返回在label里面的索引
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
#查看处理后的数据集
data.info()
1 | X = data.iloc[:,data.columns != "Survived"] |
1 | from sklearn.model_selection import train_test_split |
1 | clf = DecisionTreeClassifier(random_state=25) |
用网格搜索调整参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import numpy as np
gini_thresholds = np.linspace(0,0.5,20)
# 首先构造一个所有搜索参数的字典
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
# 实例化模型, 先不传参
clf = DecisionTreeClassifier(random_state=25)
# 实例化网格搜索API
GS = GridSearchCV(clf, parameters, cv=10)
# 对数据进行网格搜索
GS.fit(Xtrain,Ytrain)
#属性best_params_查看调整出来的最佳参数
GS.best_params_
#属性best_score_查看最佳分数
GS.best_score_
结果:0.8263665594855305
最好的参数:
{‘criterion’: ‘entropy’,
‘max_depth’: 6,
‘min_impurity_decrease’: 0.0,
‘min_samples_leaf’: 6,
‘splitter’: ‘best’}