
背景
数据和特征决定了机器学习的上限,模型和算法只是不断逼近这个上限。
不平衡程度相同(即正负样本比例类似)的两个问题,解决的难易程度也可能不同,因为问题难易程度还取决于我们所拥有数据有多大。比如在预测微博互动数的问题中,虽然数据不平衡,但每个档位的数据量都很大——最少的类别也有几万个样本,这样的问题通常比较容易解决;而在癌症诊断的场景中,因为患癌症的人本来就很少,所以数据不但不平衡,样本数还非常少,这样的问题就非常棘手。综上,可以把问题根据难度从小到大排个序:大数据+分布均衡<大数据+分布不均衡<小数据+数据均衡<小数据+数据不均衡.
举个例子,让你从一千张狗的图中找到放进去的一只猫,你看了一遍,由于狗的特征你观察的太多了,所以很难会及时分辨出哪只是猫(请忽略人的先验知识)。
常规的分类评价指标可能会失效,比如将所有的样本都分类成大类,那么准确率、精确率等都会很高。这种情况下,AUC时最好的评价指标。当你在对一个类别不均衡的数据集进行分类时得到了90%的准确度(Accuracy)。当你进一步分析发现,数据集的90%的样本是属于同一个类,并且分类器将所有的样本都分类为该类。在这种情况下,显然该分类器是无效的。并且这种无效是由于训练集中类别不均衡而导致的。
下面给出两种解决办法:
1. 数据扩充
数据不平衡,某个类别的数据量太少,那就新增一些呗,简单直接。
但是,怎么增加?如果是实际项目且能够与数据源直接或方便接触的时候,就可以直接去采集新数据。如果是比赛,那就行不通了,最好的办法就是对数据做有效增强后进行扩充。
数据增强的手段:
- 水平 / 竖直翻转
- 90°,180°,270° 旋转
- 翻转 + 旋转
- 亮度,饱和度,对比度的随机变化
- 随机裁剪(Random Crop)
- 随机缩放(Random Resize)
- 加模糊(Blurring)
- 加高斯噪声(Gaussian Noise)
以上是在实际过程中常用一些增强手段,但是除了前三种以外,其他的要慎重考虑。因为不同的任务场景下数据特征依赖不同,比如高斯噪声,在天池铝材缺陷检测竞赛中,如果高斯噪声增加不当,有些图片原本在采集的时候相机就对焦不准,导致工件难以看清,倘若再增加高斯模糊属性,基本就废了。
Image类有resize()、rotate()旋转角度和transpose()转换图像方法进行几何变换。FLIP_LEFT_RIGHT=左右互换,FLIP_TOP_BOTTOM=上下互换,ROTATE_90=顺时针旋转
附上做旋转的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26from PIL import ImageEnhance
from PIL import Image
#原图
raw_image = Image.open("./raw_images/amazon.jpg")
#旋转90°倍数
rotate_90 = raw_image.rotate(90)
rotate_180 = raw_image.rotate(180)
rotate_270 = raw_image.rotate(270)
#旋转结合翻转
flip_vertical_raw = raw_image.transpose(Image.FLIP_TOP_BOTTOM)#原始图像 flip_top_bottom上下翻转
flip_vertical_90 = rotate_90.transpose(Image.FLIP_TOP_BOTTOM)
flip_vertical_180 = rotate_180.transpose(Image.FLIP_TOP_BOTTOM)
flip_vertical_270 = rotate_270.transpose(Image.FLIP_TOP_BOTTOM)
#存储a.save('保存路径'),将a保存到制定路径
flip_vertical_raw.save("./processed_images/flip_vertical_raw.jpg")
flip_vertical_90.save("./processed_images/flip_vertical_90.jpg")
flip_vertical_180.save("./processed_images/flip_vertical_180.jpg")
flip_vertical_270.save("./processed_images/flip_vertical_270.jpg")
raw_image.save("./processed_images/amazon.jpg")
rotate_90.save("./processed_images/rotate_90.jpg")
rotate_180.save("./processed_images/rotate_180.jpg")
rotate_270.save("./processed_images/rotate_270.jpg")
2. sampler
2.1 采样
如果说类别之间的差距过大,有效的数据增强方式肯定不能弥补这种严重的不平衡,这个时候就需要在模型训练过程中对采样过程进行处理了。采样方法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集,在大部分情况下会对最终的结果带来提升。常见的采样方式分为两种:上采样和下采样,效果图如下 (图片来源见参考文献 2):
原理就是 “删图片” 和 “增加图片”,从而保证在训练过程中类别之间的数据量大致相同。所带来的影响如下
上采样:将数据量少的数据复制多份,实际上没有为模型引入更多数据,过分强调数据量少的数据,会放大这部分数据的噪音对模型的影响。
下采样:丢弃大量数据,和上采样一样会存在过拟合的问题。模型只学到了总体模式的一部分。
但总的来肯定是利大于弊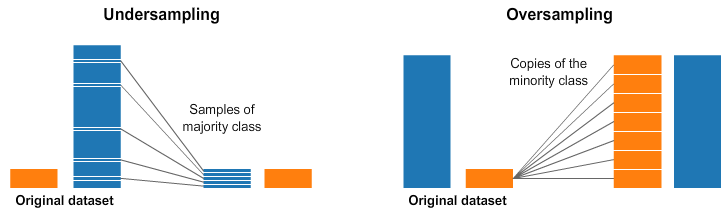
2.2 pytorch 权重采样
pytorch 在 DataLoader () 的时候可以传入 sampler ,这里只说一下加权采样1
torch.utils.data.WightedRandomSampler(weights, num_samples, replacement = True)
源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class WeightedRandomSampler(Sampler):
r"""Samples elements from [0,..,len(weights)-1] with given probabilities (weights).
Arguments:
weights (sequence) : a sequence of weights, not necessary summing up to one
num_samples (int): number of samples to draw
replacement (bool): if ``True``, samples are drawn with replacement.
If not, they are drawn without replacement, which means that when a
sample index is drawn for a row, it cannot be drawn again for that row.
"""
def __init__(self, weights, num_samples, replacement=True):
if not isinstance(num_samples, _int_classes) or isinstance(num_samples, bool) or \
num_samples <= 0:
raise ValueError("num_samples should be a positive integeral "
"value, but got num_samples={}".format(num_samples))
if not isinstance(replacement, bool):
raise ValueError("replacement should be a boolean value, but got "
"replacement={}".format(replacement))
self.weights = torch.tensor(weights, dtype=torch.double)
self.num_samples = num_samples
self.replacement = replacement
def __iter__(self):
return iter(torch.multinomial(self.weights, self.num_samples, self.replacement).tolist())
def __len__(self):
return self.num_samples
使用方法:1
2
3
4
5
6
7import torch
from torch.utils.data import DataLoader,WeightedRandomSampler
from dataset import train_dataset
weights = torch.FloatTensor([1,2,2,4,4,1])
train_sampler = WeightedRandomSampler(weights,len(train_dataset),replacement=True)
train_sampler = DataLoader(train_dataset,sampler=sampler)
解释:
- weights:指每一个类别在采样过程中得到权重大小(不要求综合为 1),权重越大的样本被选中的概率越大;
- num_samples: 共选取的样本总数,待选取的样本数目一般小于全部的样本数目;
- replacement :指定是否可以重复选取某一个样本,默认为 True,即允许在一个 epoch 中重复采样某一个数据。如果设为 False,则当某一类的样本被全部选取完,但其样本数目仍未达到 num_samples 时,sampler 将不会再从该类中选择数据,此时可能导致 weights 参数失效。
PyTorch Discussion: PyTorch Discussion:
比如说:第一类有568330个样本,第二类有43000个样本,第三类有34900个样本,第四类有20910个样本,第五类有14590个样本,最后一类有9712个样本。或者:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class_sample_counts = [568330.0, 43000.0, 34900.0, 20910.0, 14590.0, 9712.0]
weights = 1. / torch.tensor(class_sample_counts, dtype=torch.float)
samples_weights = weights[train_targets]
sampler = torch.utils.data.sampler.WeightedRandomSampler(weights=samples_weights,
num_samples=len(samples_weights),
replacement=True)
loader = torch.utils.data.DataLoader(
dataset=my_dataset,
batch_size=batch_size,
sampler=sampler,
pin_memory=False,
num_workers=number_workers,
)1
2
3
4
5
6
7
8# np.bincount计算相对应的label的个数,再转换成list
classcount = np.bincount(trainset.labels).tolist()
# 设置权重
train_weights = 1./torch.tensor(classcount, dtype=torch.float)
train__sampleweights = train_weights[trainset.labels]
# 注意,这里的num_samples就是等于train__sampleweights的长度
train_sampler = Sampler.WeightedRandomSampler(weights=train__sampleweights, num_samples=len(train__sampleweights))
trainloader = DataLoader(trainset, sampler=train_sampler, shuffle=False)3. 损失函数加权
还有一种方法是在计算损失函数过程中,对每个类别的损失做加权,具体的方式如下1
2weights = torch.FloatTensor([1,1,8,8,4])
criterion = nn.BCEWithLogitsLoss(pos_weight=weights).cuda()
4 尝试其它评价指标 (不使用Acc指标)
从前面的分析可以看出,准确度这个评价指标在类别不均衡的分类任务中并不能work,甚至进行误导(分类器不work,但是从这个指标来看,该分类器有着很好的评价指标得分)。因此在类别不均衡分类任务中,需要使用更有说服力的评价指标来对分类器进行评价。
推荐了几个比传统的准确度更有效的评价指标:
- 混淆矩阵(Confusion Matrix):使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP与TN。
- 精确度(Precision)
- 召回率(Recall)
- F1得分(F1 Score):精确度与找召回率的加权平均。
特别是:
- Kappa (Cohen kappa)
- ROC曲线(ROC Curves
5 尝试产生人工数据样本
一种简单的人工样本数据产生的方法便是,对该类下的所有样本每个属性特征的取值空间中随机选取一个组成新的样本,即属性值随机采样。你可以使用基于经验对属性值进行随机采样而构造新的人工样本,或者使用类似朴素贝叶斯方法假设各属性之间互相独立进行采样,这样便可得到更多的数据,但是无法保证属性之前的线性关系(如果本身是存在的)。
有一个系统的构造人工数据样本的方法SMOTE(Synthetic Minority Over-sampling Technique)。SMOTE是一种过采样算法,它构造新的小类样本而不是产生小类中已有的样本的副本,即该算法构造的数据是新样本,原数据集中不存在的。该基于距离度量选择小类别下两个或者更多的相似样本,然后选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声,每次处理一个属性。这样就构造了更多的新生数据。
6 尝试对模型进行惩罚
你可以使用相同的分类算法,但是使用一个不同的角度,比如你的分类任务是识别那些小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集,译者注),从而使得分类器将重点集中在小类样本身上。一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。如penalized-SVM和penalized-LDA算法。
7 训练多个弱分类器,对其投票
- 设超大类中样本的个数是极小类中样本个数的L倍,将大类中样本划分到L个聚类中,然后训练L个分类器,每个分类器使用大类中的一个簇与所有的小类样本进行训练得到。最后对这L个分类器采取少数服从多数对未知类别数据进行分类,如果是连续值(预测),那么采用平均值。
- 可以使用全部的训练集采用多种分类方法分别建立分类器而得到多个分类器,采用投票的方式对未知类别的数据进行分类,如果是连续值(预测),那么采用平均值。
8 递归地训练三个弱学习器,然后将这三个弱学习器结合起形成一个强的学习器。
一个很好的方法去处理非平衡数据问题,并且在理论上证明了。这个方法便是由Robert E. Schapire于1990年在Machine Learning提出的”The strength of weak learnability” ,该方法是一个boosting算法,它递归地训练三个弱学习器,然后将这三个弱学习器结合起形成一个强的学习器。我们可以使用这个算法的第一步去解决数据不平衡问题。
首先使用原始数据集训练第一个学习器L1。
然后使用50%在L1学习正确和50%学习错误的的那些样本训练得到学习器L2,即从L1中学习错误的样本集与学习正确的样本集中,循环一边采样一个。
接着,使用L1与L2不一致的那些样本去训练得到学习器L3。
最后,使用投票方式作为最后输出。
那么如何使用该算法来解决类别不平衡问题呢?
假设是一个二分类问题,大部分的样本都是true类。让L1输出始终为true。使用50%在L1分类正确的与50%分类错误的样本训练得到L2,即从L1中学习错误的样本集与学习正确的样本集中,循环一边采样一个。因此,L2的训练样本是平衡的。L使用L1与L2分类不一致的那些样本训练得到L3,即在L2中分类为false的那些样本。最后,结合这三个分类器,采用投票的方式来决定分类结果,因此只有当L2与L3都分类为false时,最终结果才为false,否则true。
参考文献
[1] 对非平衡数据进行处理
[2] 参考