
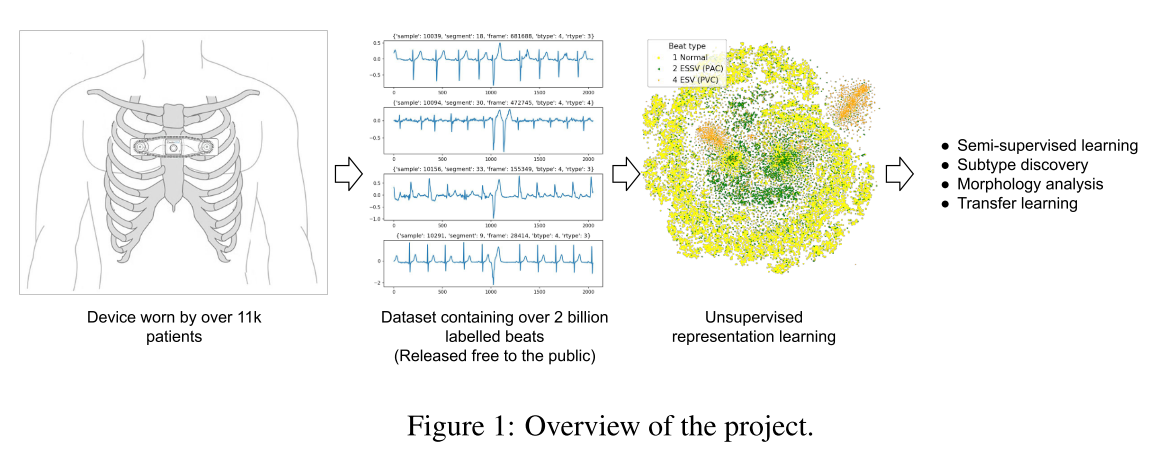
ICENTIA11K:用于心律失常亚型发现的无监督表示学习数据集
摘要:
我们发布了最大的公共心电连续原始信号数据库,包括1.1万名患者和20亿次标记的心跳。我们的目标是建立半监督心电图模型,并揭示心律失常和异常心电信号事件的未知亚型。为此,我们提出一种非监督表示学习任务,以半监督的方式进行评估。我们提供了一套不同特征提取器的基准。此外,我们对PCA embeddings的结果进行定性评估,我们发现一些已知亚型的聚类,表明representation learning在心律失常亚型发现的潜力.
1.INTRODUCTION
心律失常的检测目前是由熟悉心电图读数的心脏病学家或技术人员进行的。最近,监督机器学习已经成功地应用于某些类型的心律失常的检测
然而,可能有心电图异常需要进一步的研究,因为它们不符合目前已知的心律失常的形态。虽然心脏病学家能够看到这些差异,但如果没有数据驱动的方法,通过在多个时间点和病人身上发现相同的异常信号,很难断定这些差异是真实存在的。这激发了数据的representation learning的潜力.
1.1 OBJECTIVE
我们希望通过表现学习来提高自动心律失常检测的技术水平。理想情况下,这种representation应该尽可能多地保留关于潜在的真正心脏功能的信息。这样的表征和学习的特征提取器可以改善下游任务,这些任务需要比通常提取的预测主要心脏问题的更复杂的特征.更具体地说,我们提出了一个关于心电数据的半监督挑战
评价这种表现的客观方法是衡量它在感兴趣的任务上的表现,而在这种评价上表现最好的方法是直接在这些目标上运行一个可替代的学习任务。然而,在某些情况下,比如训练神经网络,这样做会导致输入信息的丢失(Tishby & Zaslavsky, 2015)。该过程可能会删除对发现新子类型至关重要的信息,我们将在5.2中看到一个这样的例子.
提取可以预测心律失常结果的特征,也是一个现有的研究领域(Lerma & Glass, 2016;Karpagachelvi等人,2010).
2 RELATED WORK
这一节主要介绍的是一些心电数据相关的内容,不做介绍.
3 PRIVACY CONCERNS: HEARTBEATS AS BIOMETRICS
这一部分主要介绍一些隐私问题,不做过多介绍.
4 ICENTIA11K DATASET
这一部分主要介绍ICENTIA11K这个数据集.11000个病人.
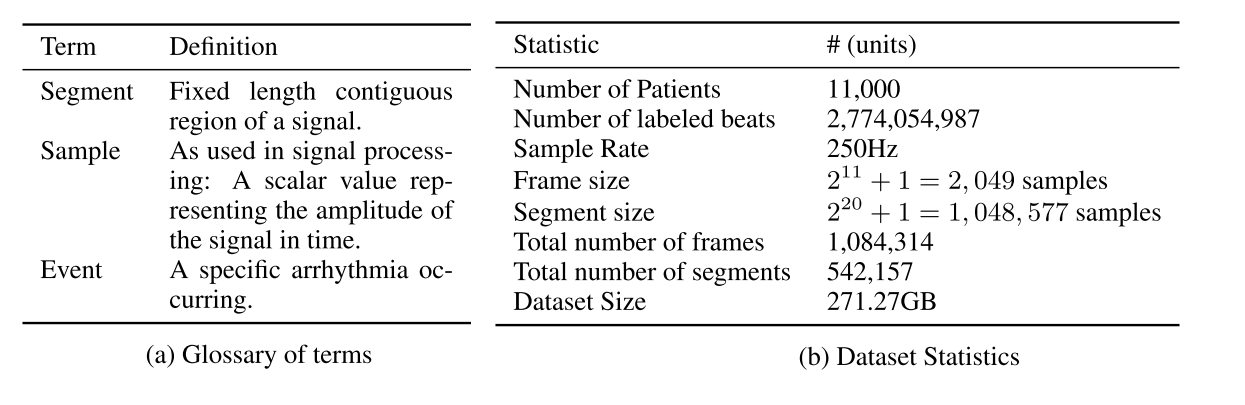
为了准备数据,我们将每个患者记录分成2^20 + 1个信号样本(70分钟)。在此基础上,我们从每一个样本列表中随机选择50个片段及其各自的标签。这样做的目标是减少数据集的大小,同时保持每个患者的公平表示。在训练数据中,我们去掉了80%的患者的标签。在剩下的20%中,有一半将用于半监督任务,另一半将作为测试数据进行评估。有关未处理和已处理数据的命名法和统计数据的详细信息可在表中找到.
我们进一步详细描述了我们将数据分为:
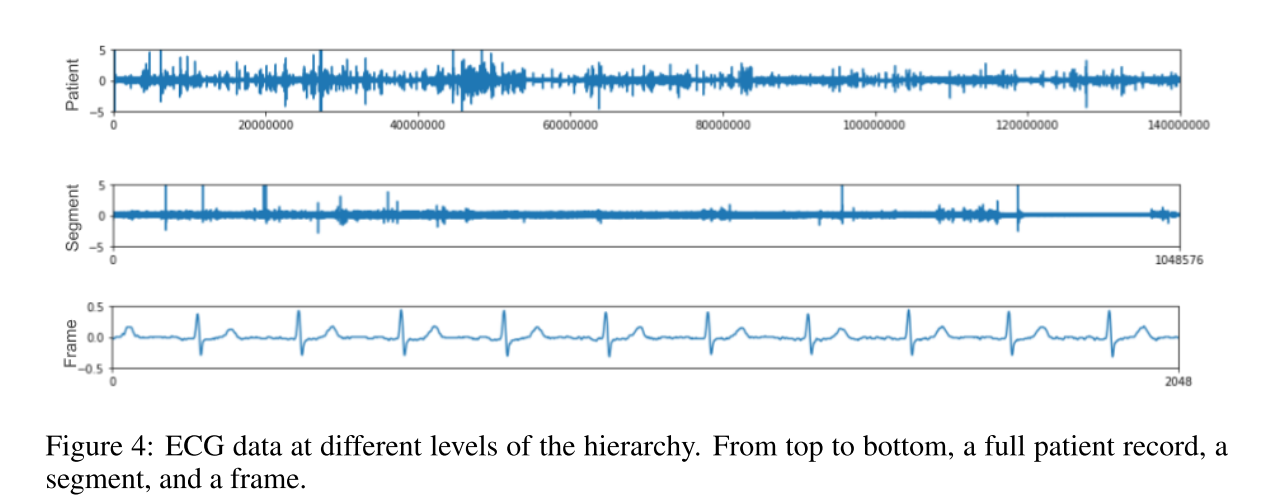
Patient level (3-14 days) At this level, the data can capture features which vary in a systematic way and not isolated events, like the placement of the probes or patient specific noise.
Segment level (approximately 1 hour) A cardiologist can look at a specific segment and identify patterns which indicate a disease while ignoring noise from the signal such as a unique signal ampli- tude. Looking at trends in the segment help to correctly identify arrhythmia as half an hour provides the necessary context to observe the stress of a specific activity.
Frame level (approximately 8 seconds) At this level, the data can capture features about the beat as well as the rhythm
在本文中,他只用到了frame-level级别的特征.我们相信用这些层次结构去处理数据可以得到一些分组信息,这些信息可以用来获得更好的结果.
5 无监督表示学习任务
虽然处理后的数据包括标记的搏动和心律失常信息,we propose an unsu- pervised representation learning challenge to the community.
这些数据的目的是开发心电信号的无监督representations表示,它可以在两个方面提供帮助:
- 1.通过使用学习表示来提高监督任务的性能。
- 通过研究representation特征的聚类来识别未知的疾病亚型
- Improve the performance of supervised tasks by using the learned representations.
- Identify unknown subtypes of disease by studying the clustering of the representations.
这些问题在下两节的定量和定性评价中讨论。本节的重点研究freme级别的embeddings,这通常足以让心脏病学家解释
5.1 QUANTITATIVE EVALUATION
对于quantitative evaluation,我们将在半监督环境中对常见的非监督算法进行基准测试,以确定基本质量.
评估包括预测数据集(样本id>10,000)中每一帧的节拍(beats)和节奏(rhythm)。beat任务是预测一个frame是否包含所有正常的心跳,或者在frame中的任何位置至少包含一个室性早搏(PVC)或房性早搏(PAC)。单独分类一个节拍而不考虑它周围的节拍可能是有挑战性的,因为例如,PAC是一个异常节拍,只是因为它出现得太快,扰乱了节奏(频率)。此外,PAC节拍的形状与正常节拍相同,因此单独来看,与正常节拍几乎没有什么不同。该模型还需要构建关于附近节拍的特征。
第二个任务是预测给定一帧的rhythm类型。对于给定的frame,分类方法必须基于输入表示来预测节律是normal、atrial fibrillation (AFib),还是atrial flutter。AFib表现为不规则的RR间期,没有明显的P波,而且两次心房激动之间的间期通常是可变的(Vollmer等人,2018年)。Flutter表现为R波的锯齿状。两者都需要一种表示法,该表示法将组成显示节拍随时间变化的表示法.
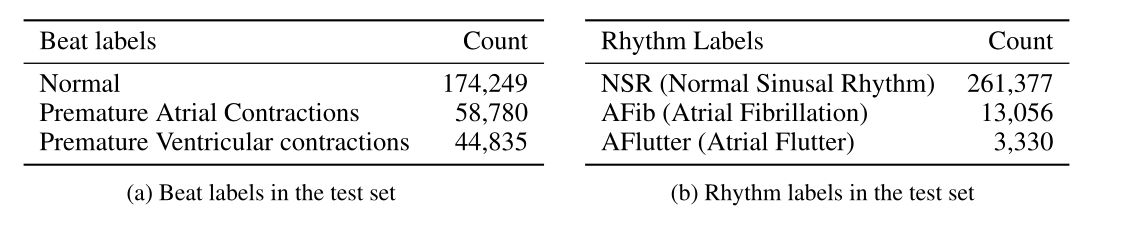
表2:测试子集中的标签计数(患者9000-10999)。每个帧都有一个标签。只提供两种类型的标签。只有这些有意义的标注用于评估并呈现给分类器
这两个任务都用在监督分类问题中,作为评估提取的特征对检测此类事件的有用性的代理
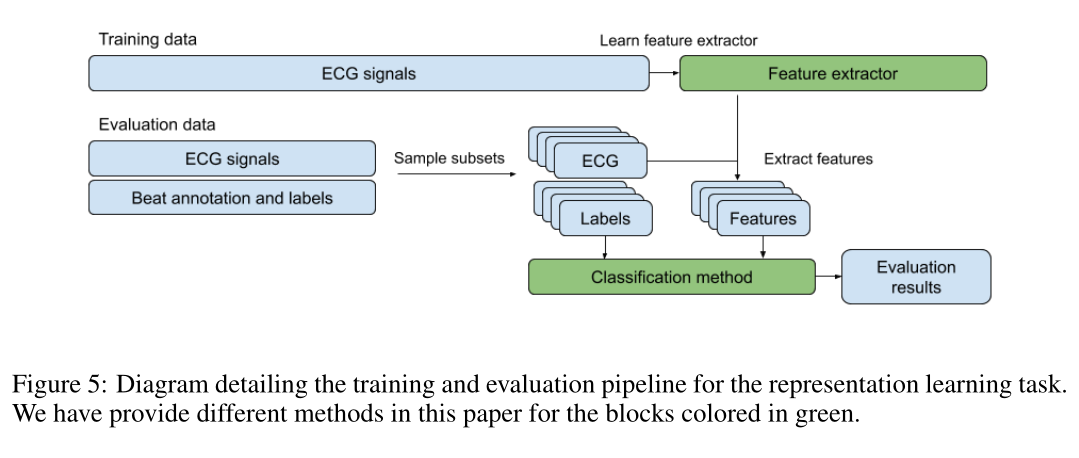
图5:详细说明表示学习任务的训练和评估的pipeline的图。对于绿色块,本文提供了不同的处理方法。
训练流程图如上,评估包括对测试集中的N个frame进行采样并使用特征提取器计算他们的representations(特征),然后使用50%的数据来训练分类方法,然后对保持的50%进行评估,使用了两种分类模型:
- (1)k=3的k近邻(KNN)方法
- (2)由维度1024、1024、512和512的4层组成的MLP方法。使用ADAM优化器对MLP模型进行了10个epoch的训练。我们应用了dropout(Sriastava等人,2014年),以防止过拟合。
每个表示都是在不知道任务的情况下学习的——在分类器的训练期间不更新特征提取模型的参数。我们提供了以下baseline特征提取方法的评估结果:
- Principal Components Analysis (PCA) 从训练数据中的3万个样本中计算出主成分。然后将测试数据投影到100、50或10个主成分上。
- Fast Fourier Transform (FFT) 计算表示1 hz到125 hz之间的频率幅度的傅立叶变换
- Periodogram 使用韦尔奇方法计算功率谱密度的估计值
- BioSPPy 使用Carreiras等人的检测算法识别每个节拍。(2015),并计算平均值和标准差,然后将它们连接在一起形成表示
- Autoencoder (Hinton,1990)由2个MLP、输入大小为2049的编码器、200维的隐藏层和100维的瓶颈表示组成。相反,解码器具有相同的体系结构。在每个非线性之前都有残差连接,并且在瓶颈层执行批量归一化(Ioffe&Szegedy,2015)。该模型与Adam(Kingma&Ba,2014年)一起以10^(−4)的学习率训练了3个epoch,具有L2损失
我们希望,在高水平异常标签(high-level abnormality labels)(如房性早搏(PAC)、室性早搏(PVC))上使用半监督设置进行评估,可以充分代表representation的质量—这些representation将被证明对发现未知疾病亚型很有用。使用两个模型来评估表示法。我们利用少量样本(N=1000和N=20000)进行评估,以模拟使用我们提供的未标记数据扩大一小部分患者队列的情况。平衡精度 用于计算性能,因为类之间存在很大的不平衡。如果一个模型要为所有样本预测同一类别,则最大平衡精度将为0.33。我们预计这在N=1000时也会成为噪声源,因为如果随机预测偶然获得几个正确的样本,则表示不足的类会对性能产生很大影响.
结果如表3所示。目前自动编码器不能像我们预期的那样运行良好。当使用KNN模型时,PCA能够执行最好的拍频检测,而MLP能够使用原始信号进行更好的预测。令人惊讶的是,rhythm检测是困难的。因为周期图和FFT捕捉信号的周期性,所以它可能比其他特征提取方法表现得更好。沃尔默等人的工作。(2018)已经表明,这在有监督的环境下是可能的
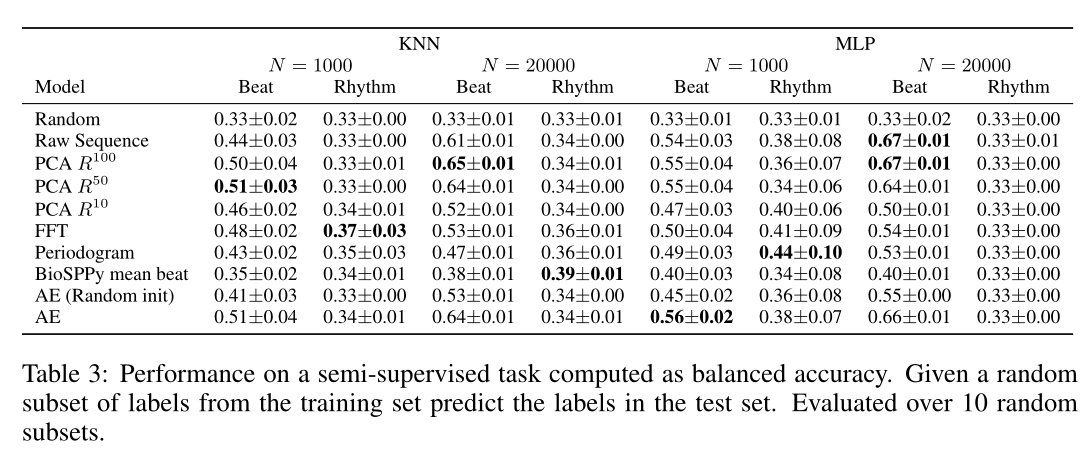
结果还显示了使用MLP作为这项任务的分类方法的问题。MLP通常需要更多的数据点来进行训练,在N=1000的情况下会出现这个问题,其中每个子集的准确度都有较高的方差。节奏分类的影响更大,其中类别不平衡,导致平衡准确率变化很大。数据越多(N=20000),方差越小。由于该任务的最终目的是学习ECG信号的更好表示,因此具有仅在较高实例计数上工作良好的强大的参数模型(如MLP)可能会将表示学习卸载到分类方法,正如我们之前提到的,这在我们的设置中不是有利的。
结果还显示了使用MLP作为这项任务的分类方法的问题。MLP通常需要更多的数据点来进行训练,在N=1000的情况下会出现这个问题,其中每个子集的准确度都有较高的方差。节奏分类的影响更大,其中类别不平衡,导致平衡准确率变化很大。数据越多(N=20000),方差越小。由于该任务的最终目的是学习ECG信号的更好表示,因此具有仅在较高实例计数上工作良好的强大的参数模型.
5.2 QUALITATIVE EVALUATION
医学文献已经讨论了多种类型的PVC(Kanei等人,2008;Phibbs,2006)。PVC可以是单态的,也可以是多态的(具有不同的形态)。此外,PVCs也可以是多焦点的,表现为不同的形状。当它从右心室发出时,它在V1导联上有一个占优势的S波。而如果从左心室Phibbs产生,它有一个占主导地位的R波.
我们通过使用图6中的t-SNE查看40,000个frame的PCA编码来研究信号的聚类。曲线图清楚地显示了PVC的两个群集,我们可以将其解释为这种心律失常的两种不同的形态。我们注意到,这些很容易看到,因为我们用不同的颜色来突出这些点,但似乎还有剩余的簇没有分析过。对于PVC具有两个簇之间的相关性和PVC是多形态的方面,医学研究人员可能会感兴趣,以便进一步探索由不同特征提取器创建的该空间中的簇。
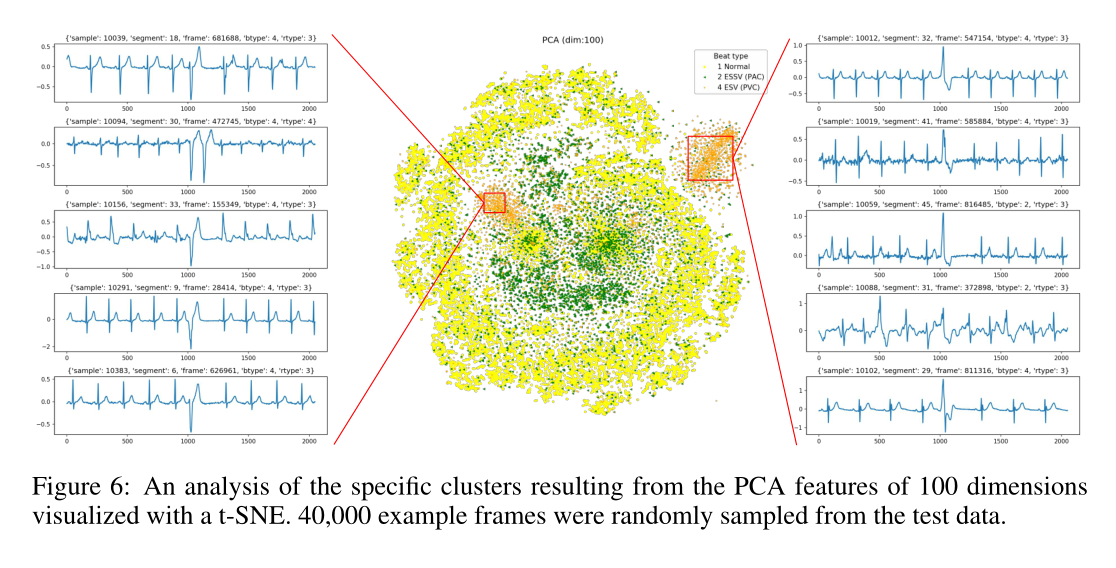
图6:通过t-SNE可视化的100维的PCA特征产生的特定群集的分析。从测试数据中随机抽取了40,000个示例frame。
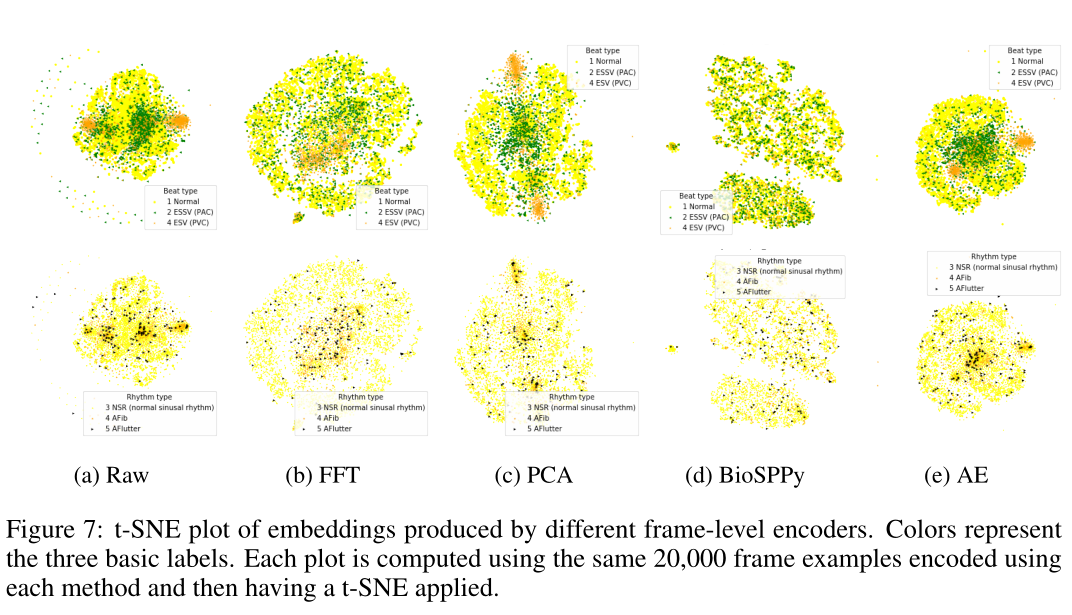
图7所示的任何其他编码方法也显示了与PVC和PAC相关的集群。值得注意的是,FFT和BioSppy不会将PVC分成两个簇。虽然我们可以观察到节奏有一定的分组,但在定量评价中似乎并不显着。
6 CONCLUSION
像CartioSTA这样的单导联心脏监护仪越来越普遍,心脏病专家有可能了解更多关于心律失常和相关心脏疾病的知识。然而,如此大量的数据意味着人工分析不再实用.机器学习通过训练基于人类专家标签的模型来预测正确的诊断,已经在医学领域得到了广泛的应用。监督学习在医学领域起到了很好的辅助作用,但是它很难提供人类知识之外的信息。,此外,某些人体信号可能非常复杂,并隐含不易实现的非线性特征难以被可人工识别的。目前,表征学习方法在解开复杂特征方面具有潜力,并有可能揭示某些疾病的新信号结构,这些结构可能与临床表现相关。
通过发布这个数据集,我们相信我们可以利用无监督的表示学习专业知识,不仅帮助实现样本数量较少的训练模型,而且有可能发现新的疾病并识别与其相关的模式。
我们提出了一种评估pipeline,用于学习特征提取器和评估提取的特征,使用已知心律失常作为代理来衡量特征的有用性。此外,我们还提供了不同特征提取方法下的frame级表示的基线结果。我们的数据准备提供了三个级别的层次结构,虽然我们没有提供利用这一点,但未来的工作可以利用这一上下文来提取更好的表示,也许还会在表示空间中找到更有趣的结构。我们还相信这个数据集可以作为机器学习的其他领域的基准,例如异常和离群值检测以及分层序列建模.